Configuration
The heart of SQLFlow is the pipeline configuration file. Each configuration file specifies:
- Command Configuration
- Pipeline configuration
- Source: Input configuration
- Handler: SQL transformation
- Sink: Output configuration
The following image shows a sample configuration file:
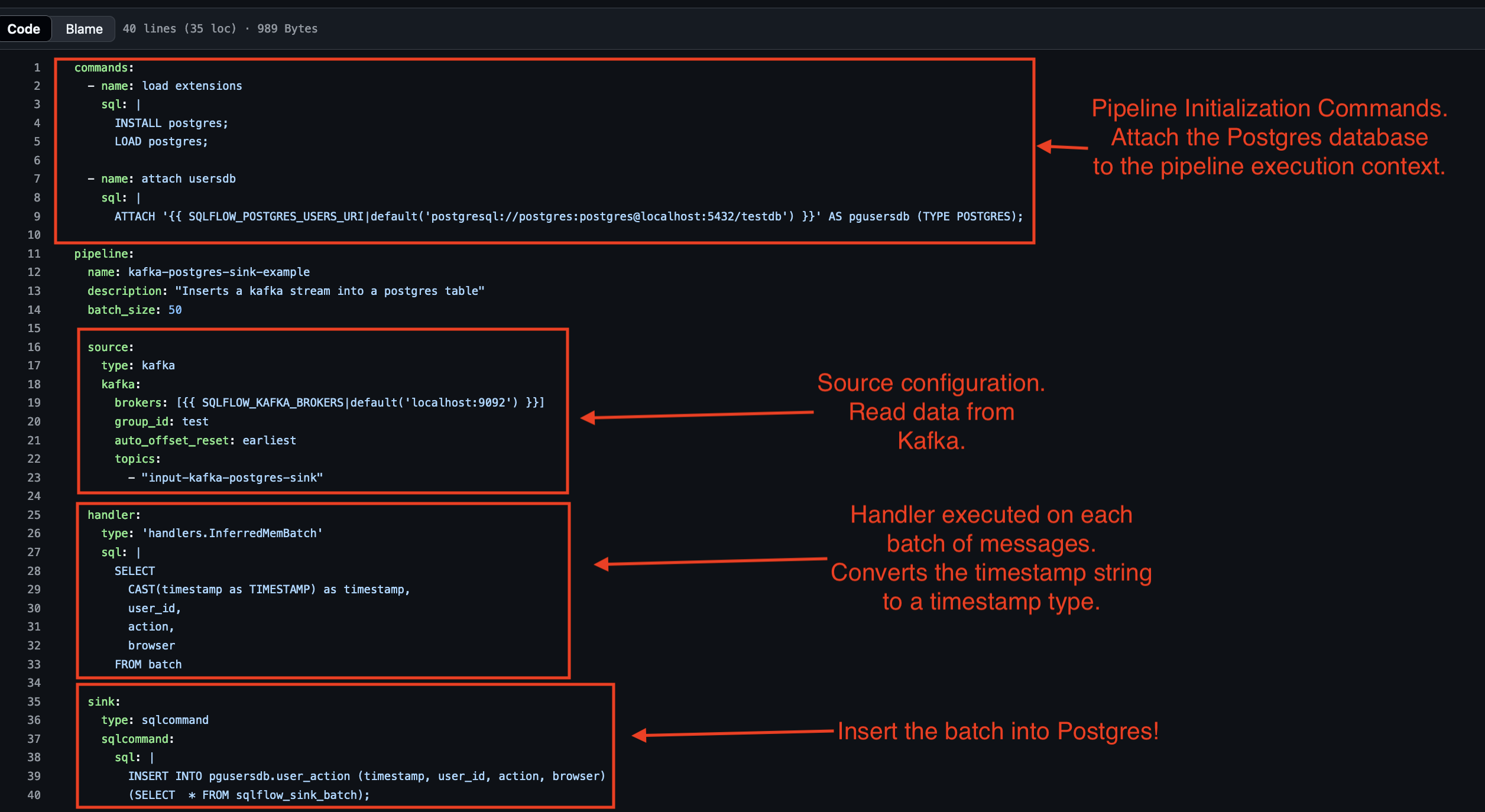
Every instance of SQLFlow needs a pipeline configuration file. Configuration examples are availble in turbolytics/sql-flow repo:
https://github.com/turbolytics/sql-flow/tree/main/dev/config/examples
Command Configuration
Commands are SQL statements executed during pipeline initialization. These commands allow for ATTACHing databases to the pipeline context. The commands directive is a top level directive in the configuration file.
commands:
- name: load extensions
sql: |
INSTALL postgres;
LOAD postgres;
- name: attach usersdb
sql: |
ATTACH '{{ SQLFLOW_POSTGRES_USERS_URI|default('postgresql://postgres:postgres@localhost:5432/testdb') }}' AS pgusersdb (TYPE POSTGRES, READ_ONLY);
This example loads the DuckDB postgres extension and then attaches the postgres database to the pipeline context. The commands directive is optional.
It contains an array of commands to execute during pipeline initialization. The commands are executed in order.
Pipeline Configuration
The pipeline configuration is the core of SQLFlow. It specifies the input source, handler, and output sink. The top level pipeline directive contains the following keys:
pipeline:
name: <pipeline-name>
description: <pipeline-description>
batch_size: <batch size>
source:
...
handler:
...
sink:
...
The batch size is the number of rows to process in a single batch. The batch size is optional and defaults to 1.
A batch of 100 means 100 records will be read into SQLFlow before the handler processes the batch.
Source Configuration
SQLFlow currently supports 2 sources:
- Kafka
- Websocket
The following shows an example of each:
pipeline:
...
source:
type: kafka
kafka:
brokers: [{{ SQLFLOW_KAFKA_BROKERS|default('localhost:9092') }}]
group_id: test
auto_offset_reset: earliest
topics:
- "input-simple-agg-mem"
pipeline:
...
source:
type: websocket
websocket:
uri: 'wss://jetstream2.us-east.bsky.network/subscribe?wantedCollections=app.bsky.feed.post'
Notice how each concrete source is located under the corresponding key. When type: kafka the kafka configuration is expected under the kafka key.
Handler Configuration
Handlers are the heart of the SQLFlow pipeline. Handlers contain the SQL to execute against the input source. The handler configuration is located under the handler key.
pipeline:
...
handler:
type: 'handlers.InferredMemBatch'
sql: |
SELECT * FROM batch
SQLFlow supports 3 handlers:
- handlers.InferredMemBatch: Infers the table schema using DuckDB Schema Inference, buffers the batch in memory.
- handlers.InferredDiskBatch: Infers the table schema using DuckDB Schema Inference, buffers the batch in disk.
- handlers.StructuredBatch: Requires the schema to be specified in the configuration file. This supports either in memory or on disk.
The most important part of the handler is the sql key. This is the SQL to execute against the input batch. The result of the SQL is written to the output sink.
The batch Table
Sink Configuration
SQLFlow supports the following sinks:
- Console (example)
- Kafka (example)
- Postgres (example)
- Filesystem
- Iceberg (example)
- Any output that DuckDB supports through the
sqlcommandsink.
User Defined Functions (UDF)
SQLFlow supports User Defined Functions (UDF) in the configuration file.
https://github.com/turbolytics/sql-flow/blob/main/dev/config/examples/udf.yml
UDF Supports loading a function from the $PYTHONPATH. This will require that the end user either:
- Loads their python file (without additional dependencies) into the docker container (such as -v /path/to/udf.py:/app/plugins/udf.py) and then adds the /app/plugins to the python path.
- Create a new dockerfile based on turbolytics/sql-flow and adds copying UDF code and installs requirements, then puts the UDF code on the $PYTHONPATH
Testing Configuration
SQLFlow supports testing the configuration file. The configuration file can be tested using the following command:
python3 cmd/sql-flow.py config validate $(pwd)/dev/config/examples/bluesky/bluesky.kafka.raw.yml
Templating
SQLFlow files support templating using the python jinja library (https://jinja.palletsprojects.com/en/stable/)
Environmental Variables
SQLFlow supports environmental variables in the configuration file.
Any variable starting with SQLFLOW_ will be replaced with the environmental variable value. Consider the following example:
brokers: [{{ SQLFLOW_KAFKA_BROKERS|default('localhost:9092') }}]
This will replace SQLFLOW_KAFKA_BROKERS with the environmental variable value. If the environmental variable is not set, it will default to localhost:9092.
Example Configuration Options
The following yaml lists the full set of available configuration options:
# List of SQL commands to execute before processing the pipeline.
commands:
-
# Name of the command for reference.
name: <string>
# SQL statements to execute.
sql: <string>
# Predefined SQL tables used in the pipeline.
tables:
# List of tables with their SQL definitions and management configurations.
sql:
-
# Name of the table.
name: <string>
# SQL statements to create the table and indexes.
sql: <string>
# Manager for handling windowing operations and clean-up.
manager:
# Tumbling window management for table data.
tumbling_window:
# SQL query to collect closed tumbling windows.
collect_closed_windows_sql: <string>
# SQL query to delete closed tumbling windows.
delete_closed_windows_sql: <string>
# Configuration for the data sink.
sink:
# Sink identifier.
type: kafka | noop | iceberg | console | sqlcommand
# Kafka-specific sink configuration.
kafka:
# List of Kafka brokers for publishing data.
brokers:
- <array>
# Kafka topic where processed data will be written.
topic: <string>
# Iceberg-specific sink configuration.
iceberg:
# Name of the Iceberg catalog (e.g., 'sqlflow_test').
catalog_name: <string>
# Name of the Iceberg table (e.g., 'default.city_events').
table_name: <string>
# Sink type that executes a SQL command.
sqlcommand:
# SQL command that inserts data into a database.
sql: <string>
# List of User-Defined Functions (UDFs) to be used in SQL queries.
udfs:
-
# Name of the function as referenced in SQL queries.
function_name: <string>
# Python import path where the function is defined.
import_path: <string>
# Main pipeline configuration.
pipeline:
# Name of the pipeline.
name: <string>
# Description of the pipeline.
description: <string>
# Number of messages processed in a batch.
batch_size: <integer>
# Time interval to flush batches in seconds.
flush_interval_seconds: <integer>
# Configuration for the data source.
source:
# Error handling strategy for the source.
on_error:
# Defines how errors should be handled.
policy: raise | ignore
# Type of source.
type: kafka | websocket
# Kafka-specific source configuration.
kafka:
# List of Kafka broker addresses.
brokers:
- <array>
# Kafka consumer group ID.
group_id: <string>
# Offset reset policy.
auto_offset_reset: earliest | latest
# List of Kafka topics to consume.
topics:
- <array>
# WebSocket-specific source configuration.
websocket:
# WebSocket URI to connect to (e.g., 'wss://example.com').
uri: <string>
# Data processing configuration.
handler:
# Type of handler used for processing.
type: handlers.InferredDiskBatch | handlers.InferredMemBatch | handlers.StructuredBatch
# SQL query to process each batch.
sql: <string>
# Configuration for the data sink.
sink:
# Type of sink (supports 'kafka' or 'noop').
type: kafka | noop | iceberg | console | sqlcommand
# Kafka-specific sink configuration.
kafka:
# List of Kafka brokers for publishing data.
brokers:
- <array>
# Kafka topic where processed data will be written.
topic: <string>
# Iceberg-specific sink configuration.
iceberg:
# Name of the Iceberg catalog (e.g., 'sqlflow_test').
catalog_name: <string>
# Name of the Iceberg table (e.g., 'default.city_events').
table_name: <string>
# Sink type that executes a SQL command.
sqlcommand:
# SQL command that inserts data into a database.
sql: <string>