SQLFlow: Join Kafka With Postgres To Enrich Real time Data Streams
Combining real-time streaming data with operational data, from systems like #postgresql, is a common challenge. Whether you're enriching live transaction streams with user profiles, correlating sensor data with metadata, or performing dynamic lookups for analytics, the ability to join these two types of data sources is essential.
This tutorial will guide you through building an end-to-end pipeline using SQLFlow, a powerful tool for processing and transforming data streams. You'll learn how to:
- Ingest data from Kafka, a popular distributed streaming platform, to process real-time events like user transactions.
- Enrich the streaming data with reference data from PostgreSQL, a widely used relational database, to add context and insights.
- Output enriched data to your console or other destinations (such as Kafka), enabling further analysis, visualization, or downstream processing.
By the end of this tutorial, you'll have a working pipeline that combines the speed of Kafka streams with the robustness of PostgreSQL lookups, empowering you to tackle real-world use cases like fraud detection, customer profiling, or IoT event enrichment. Whether you're just starting with stream processing or looking for a practical SQL-based approach, this hands-on guide will provide everything you need to get started.
Prerequisites
This tutorial uses SQLflow to read data from Kafka, join the data with Postgres, and write the outputs to the console:
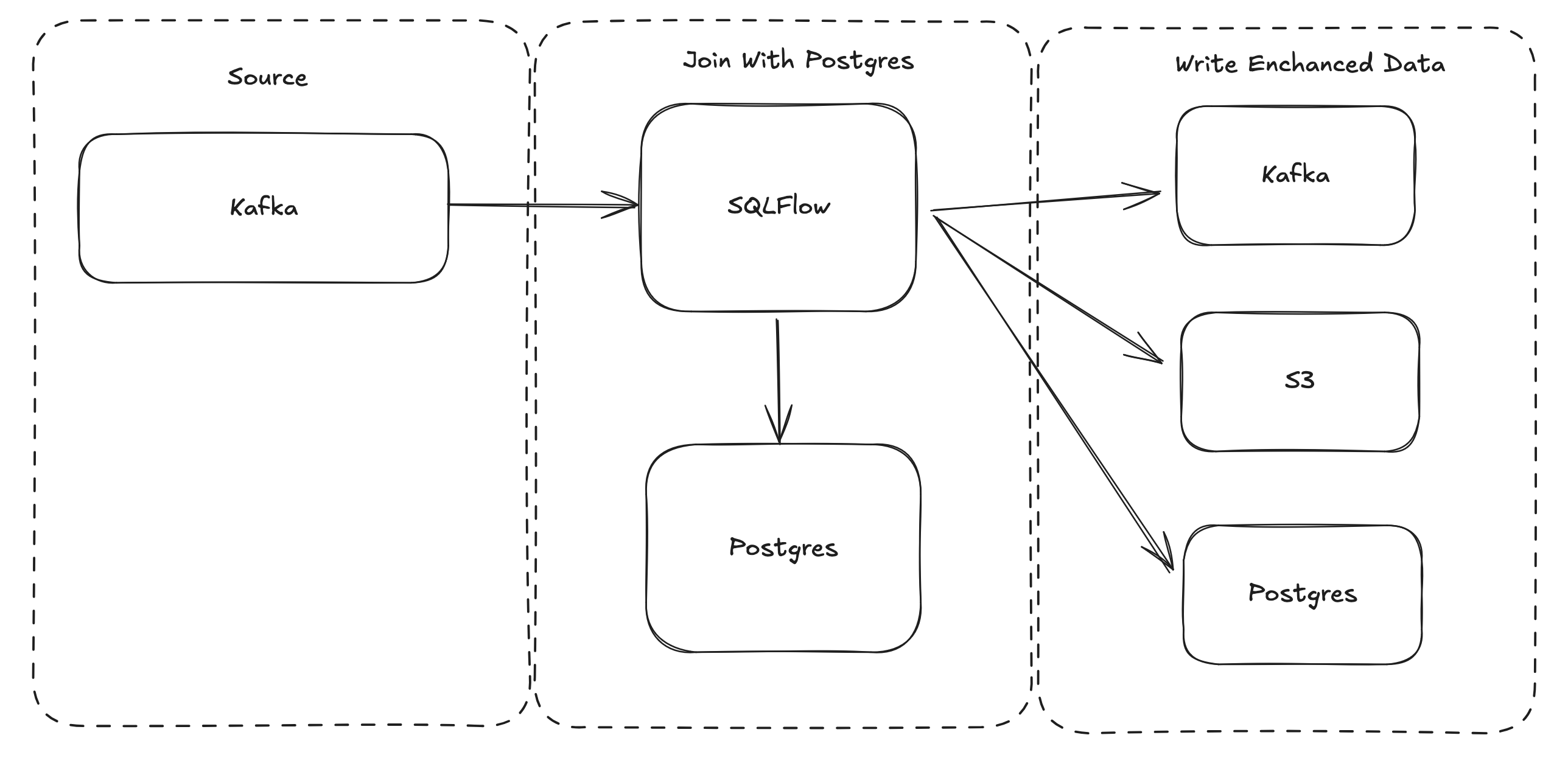
A couple of per-requisites are required to start:
Install SQLFlow
- Clone the turbolytics/sql-flow repo: this contains the example pipeline configuration files and docker compose setup for this tutorial
- Pull the turbolytics docker image: The image is necessary to execute the SQLFlow pipeline.
Start Kafka and Postgres
SQLFlow includes a docker compose file with both kafka and postgres configured. Start it using the following command:
cd /path/to/sql-flow
docker-compose -f dev/kafka-single.yml up -d
Define the Pipeline
The core of any SQLFlow pipeline is its configuration file, which defines how data flows through the system—from input sources to transformations and output destinations. In this tutorial, we’ll set up a pipeline to join real-time Kafka data with reference data stored in PostgreSQL and output the enriched results. Below is the explanation of the working pipeline configuration file.
Pipeline Configuration Overview
The pipeline consists of the following key components:
Input Source:
- Data is ingested from a Kafka topic called input-user-clicks-demo.
- The input format is JSON, allowing for structured message processing.
Transformation:
- SQLFlow executes a SQL query to join the Kafka data with a PostgreSQL table (user_profiles).
- The query enriches the streaming data with user profile details.
Output Sink:
- The enriched data is written to the console, for demo purposes. SQLflow supports Kafka, Iceberg and any other Output source supported by DuckDB, including: Postgres and S3.
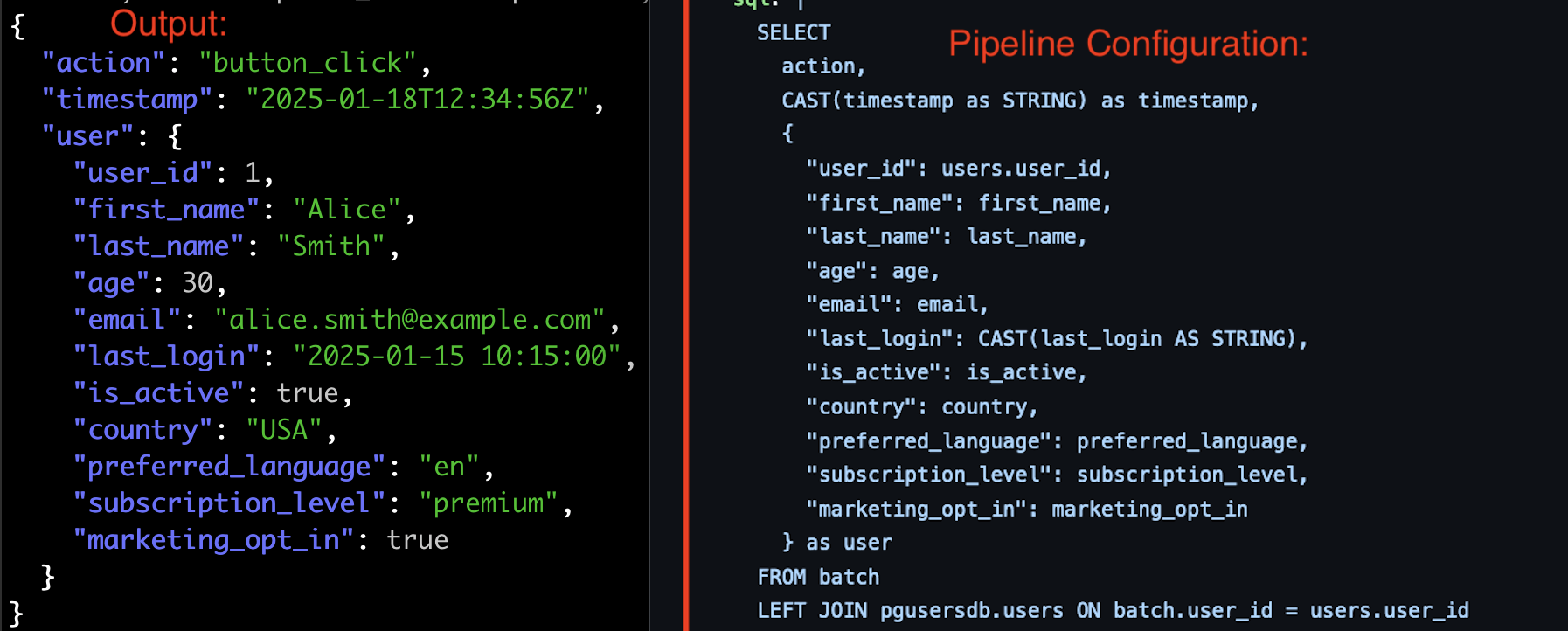
Configuration File
The following image shows the configuration file required to run the pipeline (source):

SQLFlow connects real-time Kafka streams with static PostgreSQL data to create enriched datasets, using this pipeline configuration. Next, you’ll deploy and run the pipeline to see it in action!
Run the Pipeline
Start SQLFlow
docker run -v $(pwd)/dev:/tmp/conf -e SQLFLOW_POSTGRES_USERS_URI=postgresql://postgres:[email protected]:5432/testdb -e SQLFLOW_KAFKA_BROKERS=host.docker.internal:29092 turbolytics/sql-flow:0.6.0 run /tmp/conf/config/examples/kafka.postgres.join.yml
2025-01-20 01:30:46,163 [INFO] executing command load extensions: INSTALL postgres;
LOAD postgres;
2025-01-20 01:30:47,193 [INFO] executing command attach usersdb: ATTACH 'postgresql://postgres:[email protected]:5432/testdb' AS pgusersdb (TYPE POSTGRES, READ_ONLY);
2025-01-20 01:30:47,273 [INFO] consumer loop starting
This command starts SQLFlow. SQLFlow will idle waiting for messages from Kafka. Notice the log statements show that postgres is attached.
Publish a Message to Kafka
The next step is to publish a message to kafka. The demo pretends that this message represents a clickstream event that a user might perform, such as a button click or a page load, or a view.
- Start the kafka console producer publishing to the topic SQLFlow is reading from:
docker exec -it kafka1 kafka-console-producer --bootstrap-server=kafka1:9092 --topic=input-user-clicks-demo
- Publish a Message to the input topic:
>{"action": "button_click", "timestamp": "2025-01-18T12:34:56Z", "user_id": 1}
>
Observe SQLFlow Output for the Enriched Message!
You should see a console output from SQLFlow, shortly after pasting the test message. The output should look like the following:
{"action": "button_click", "timestamp": "2025-01-18T12:34:56Z", "user": {"user_id": 1, "first_name": "Alice", "last_name": "Smith", "age": 30, "email": "[email protected]", "last_login": "2025-01-15 10:15:00", "is_active": true, "country": "USA", "preferred_language": "en", "subscription_level": "premium", "marketing_opt_in": true}}
Notice how the output message matches the SQL handler:
Advanced Topics
If you liked this post and are looking to get your hands dirty, the following are additional ways SQLFlow can be used!
Replace Console Sink with Kafka:
- Stream enriched data to Kafka for downstream consumers.
- Enable scalability and fault-tolerant delivery with partitioning and replication.
Stateful Processing with PostgreSQL:
- Track dynamic information like user sessions or rolling metrics.
- Use PostgreSQL as a durable sink for state updates and efficient queries.
Advanced Aggregations and Windowing:
- Perform hourly, daily, or session-based aggregations.
- Store results in PostgreSQL for persistent analysis.
Input Schema Validation:
- Ensure data integrity by validating schemas at ingestion.
- Route invalid messages to a dead-letter queue (DLQ).
Observability and Monitoring:
- Use Prometheus and Grafana to track throughput, latency, and errors.
- Set up logging and alerts to maintain pipeline health.
Conclusion
Building stream processing pipelines often requires navigating complex frameworks, writing intricate code, and managing a myriad of configurations to handle real-time data effectively. Traditional approaches can be overwhelming, especially when dealing with distributed systems like Kafka or integrating with relational databases like PostgreSQL. Tasks like joining streams with reference data, ensuring stateful processing, and managing outputs typically involve significant development effort and expertise.
SQLFlow changes the game by simplifying stream processing to the level of writing a single SQL statement. By abstracting away the complexities, SQLFlow allows developers to focus on the logic of their data pipelines without worrying about the underlying infrastructure. Whether you’re enriching Kafka streams, performing real-time aggregations, or joining multiple data sources, SQLFlow provides a seamless, SQL-centric approach to handle it all. With just one configuration file, you can create powerful, production-grade pipelines that are scalable, maintainable, and easy to extend—making the impossible feel effortless.