Using SQLFlow to Sink 5000 Rows / Second from Kafka To Postgres
Modern data workflows often require streaming data from real-time sources like Kafka into reliable, queryable storage systems such as PostgreSQL. While this task is essential for many analytics and operational pipelines, implementing it can be complex—often involving custom code, multiple tools, and extensive configuration.
With SQLFlow, you can define the entire pipeline to sink data from Kafka to PostgreSQL using just a single SQL statement. By abstracting away the complexities of stream processing, SQLFlow allows you to focus on transforming and storing your data without the need for extensive boilerplate or glue code.
In this blog post, we’ll guide you through setting up a SQLFlow pipeline to ingest real-time data from Kafka, transform it on the fly, and sink it into a PostgreSQL database—all with minimal effort. Whether you're building a data lake, powering real-time dashboards, or simply archiving event data, SQLFlow makes the process intuitive and scalable.
This article is a continuation of a previous article on using SQLFlow to join kafka data with data in postgres: https://www.linkedin.com/pulse/sqlflow-join-kafka-postgres-enrich-real-time-data-streams-cymue/
This article will teach you how to:
- Ingest data from Kafka to process real-time events like user transactions.
- Transform the data in-flight, using SQLFlow.
- Insert (Sink) transformed data into postgres.
Prerequisites
This tutorial uses SQLflow to read data from Kafka, transform the data in SQLFlow, and insert the transformed data into postgres:

Install SQLFlow
- Clone the turbolytics/sql-flow repo: this contains the example pipeline configuration files and docker compose setup for this tutorial
- Pull the turbolytics docker image: This will be used to run the pipeline.
Start Kafka and Postgres
SQLFlow includes a docker compose file with both kafka and postgres configured. Start it using the following command:
cd /path/to/sql-flow
docker-compose -f dev/kafka-single.yml up -d
Define the Pipeline
The core of any SQLFlow pipeline is its configuration file, which defines how data flows through the system—from input sources to transformations and output destinations. In this tutorial, we’ll set up a pipeline to process kafka data and insert the outputs into PostgreSQL. Below is the explanation of the working pipeline configuration file.
Pipeline Configuration Overview
The pipeline consists of the following key components:
Input Source:
- Data is ingested from a Kafka topic called input-kafka-postgres-sink.
- The input format is JSON, allowing for structured message processing.
Transformation:
- SQLFlow executes a SQL to select data off of kafka.
- The query casts the timestamp string to a timestamp type
Output Sink:
- The enriched data is written to postgres. SQLflow supports Kafka, Iceberg and any other Output source supported by DuckDB, including s3.
Configuration File
The following image shows the configuration file for the pipeline source:
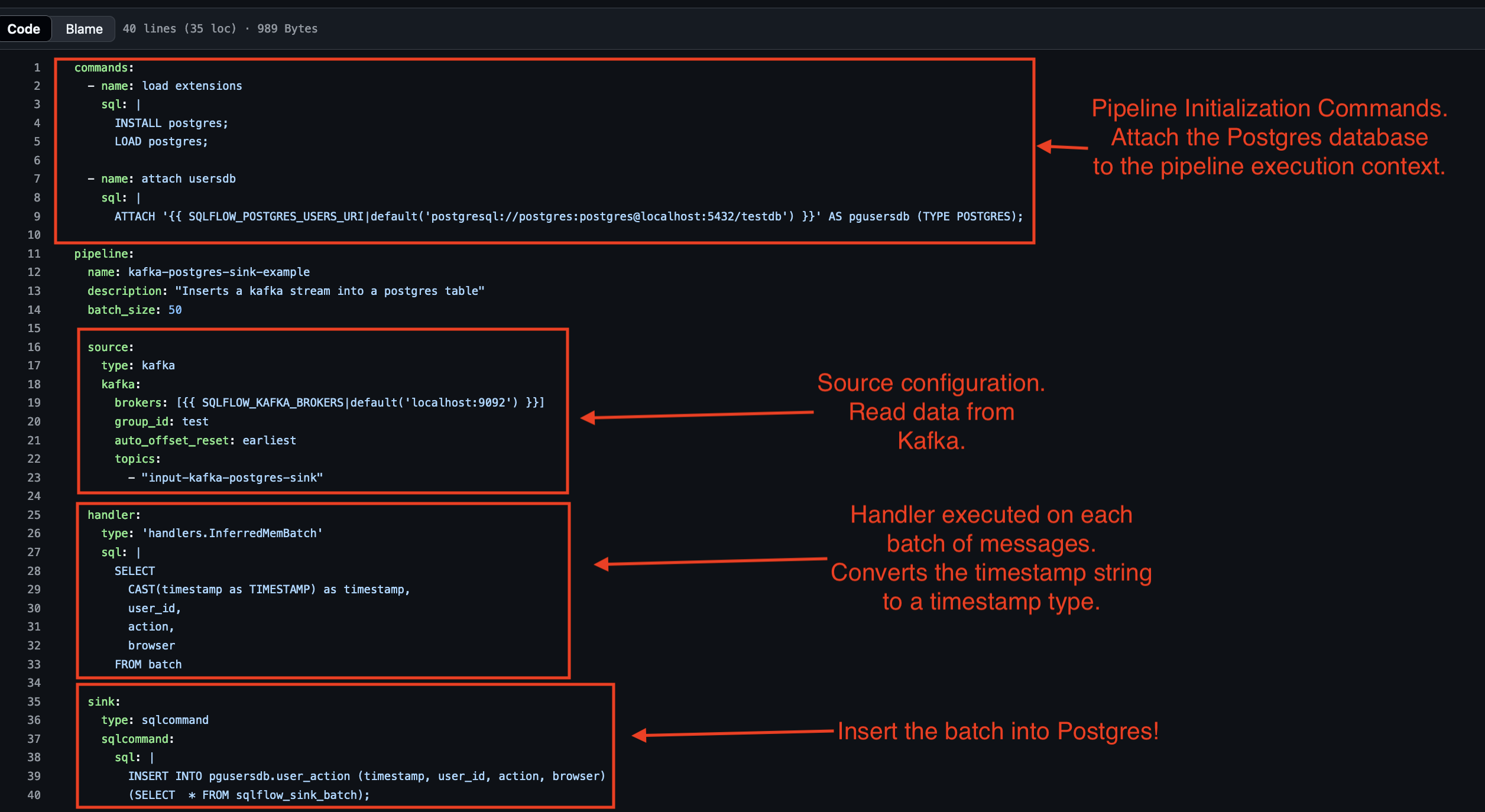
SQLFlow uses this pipeline to stream real-time data from Kafka to PostgresSQL. Next, you’ll deploy and run the pipeline to see it in action!
Run the Pipeline
Start SQLFlow
docker run -v $(pwd)/dev:/tmp/conf -e SQLFLOW_POSTGRES_USERS_URI=postgresql://postgres:[email protected]:5432/testdb -e SQLFLOW_KAFKA_BROKERS=host.docker.internal:29092 turbolytics/sql-flow:latest run /tmp/conf/config/examples/kafka.postgres.sink.yml
2025-01-22 01:02:13,322 [INFO] executing command load extensions: INSTALL postgres;
LOAD postgres;
2025-01-22 01:02:14,638 [INFO] executing command attach usersdb: ATTACH 'postgresql://postgres:[email protected]:5432/testdb' AS pgusersdb (TYPE POSTGRES);
2025-01-22 01:02:14,719 [INFO] consumer loop starting
This command starts SQLFlow. SQLFlow will idle waiting for messages from Kafka. Notice the log statements show that postgres is attached.
Publish a Message to Kafka
The next step is to publish a message to kafka. The demo pretends that this message represents a clickstream event that a user might perform, such as a button click or a page load, or a view.
- Check to make sure that user_actions is empty
docker exec -it dev_postgres_1 psql -U postgres -d testdb -c "select * from user_action";
timestamp | user_id | action | browser
-----------+---------+--------+---------
(0 rows)
- Start the kafka console producer publishing to the topic SQLFlow is reading from:
docker exec -it kafka1 kafka-console-producer --bootstrap-server=kafka1:9092 --topic=input-kafka-postgres-sink
>
- Publish a Message
>{"timestamp": "2025-01-18T12:34:56Z", "user_id": "u12345", "action": "button_click", "browser": "Chrome"}
Query the user_actions Postgres Table!
Shortly after sending the message, the data should become available in Postgres:
docker exec -it dev_postgres_1 psql -U postgres -d testdb -c "select * from user_action";
timestamp | user_id | action | browser
---------------------+---------+--------------+---------
2025-01-18 12:34:56 | u12345 | button_click | Chrome
(1 row)
You just streamed data from kafka to postgres with a 40 line configuration file!
Turbocharging the Throughput: Inserting 1000's of Rows / Second
The current setup is based on a single message batch. This means that every message will trigger a corresponding insert query. SQLFlow leverages pyarrow and DuckDB for super fast pipeline execution. This speed can be leveraged against larger batches. A batch size of 100 increases throughput to 6000 messages / second!!!
- Publish 200k messages
python3 cmd/publish-test-data.py --num-messages=200000 --topic="input-kafka-postgres-sink" --fixture=user_action
- Start SQLFlow specifying a batch size of 100
docker run -v $(pwd)/dev:/tmp/conf -e SQLFLOW_BATCH_SIZE=200 -e SQLFLOW_POSTGRES_USERS_URI=postgresql://postgres:[email protected]:5432/testdb -e SQLFLOW_KAFKA_BROKERS=host.docker.internal:29092 turbolytics/sql-flow:latest run /tmp/conf/config/examples/kafka.postgres.sink.yml --max-msgs-to-process=200000
- Query user_actions postgres to show output
docker exec -it dev_postgres_1 psql -U postgres -d testdb -c "select COUNT(*) from user_action";
count
--------
200000
(1 row)
SQLFlow easily handles inserting 5000+ messages / second !!
2025-01-22 01:26:10,450 [INFO] 5325.0: reqs / second
2025-01-22 01:26:10,469 [INFO] max messages reached
2025-01-22 01:26:10,480 [INFO] consumer loop ending: total messages / sec = 5321.0
Conclusion
Streaming data into PostgreSQL from Confluent #Kafka often involves juggling multiple tools, frameworks, and custom code, making the process complex and time-consuming. With SQLFlow, this complexity is eliminated. SQLFlow simplifies the integration by allowing you to define the entire pipeline—ingestion, transformation, and data sinking—using a single SQL statement.
SQLFlow enables anyone familiar with SQL to achieve high performance stream processing and insertion into postgres. SQLFlow makes getting data into postgres vendors like: Amazon Web Services (AWS), DigitalOcean, Aiven, Crunchy Data, Timescale, Supabase, or Google Cloud easier than ever. A single small python instance of SQLFlow easily inserts 1000's of rows a second into small postgres instances, thanks to The Apache Software Foundation #arrow and DuckDB !
Whether you're archiving data, powering real-time dashboards, or enriching data streams, SQLFlow provides an intuitive and scalable solution for sinking Kafka data into PostgreSQL. By leveraging the power of SQL, you can focus on what matters most: extracting insights and building value from your data. Start simplifying your data pipelines with SQLFlow today!